Artifacts Management in Container-Native Workflows (Part 2)
In Part 1, I discussed how we chose object storage (for example, AWS S3) to store artifacts for container-native workflows in Argo. I discussed the use of init and post containers along with main (user-specified) container to help orchestrate artifact storing and retrieving for executing serial and parallel steps in a workflow. In this blog post, I will cover in-depth the implementation details of the solution.
Execution Script
Argo’s goal is to provide an automated solution to use artifacts within container-native workflows without users necessarily modifying their existing container images when running a step in a container workflow. Given this constraint, the main problem we need to solve is the ability to copy out the newly generated artifacts before main container exits.
One simple solution could be to mount a volume underneath the user-specified path so all the newly generated artifacts are saved into the volume. The problem with this approach is that when a user container (in a workflow step) defines a desired artifact, say, /src/app.jar, and if we mount a volume under /src, all the other existing files in /src will be masked and thus cannot be seen by the main container of the workflow step. This is clearly not desired as we cannot assume the files in the path are not needed as they can possibly be overwritten.
To avoid this problem, Argo uses an execution script (executor.sh) which acts as the new entrypoint (or commands) of the container. This script is composed during runtime and contains the real entrypoint and also copies all the newly generated artifacts to a desired path afterwards.
Here is an example:
User has a docker image which will generate an output artifact under /src/app.jar
The execution script will be something like
Where /ax-artifact-scratch has a volume underneath so that we can later access it from another container (sidecar) and upload to S3. The path name is is purposefully chosen to be complex to avoid collision.
This seems all good except we still don’t know the real entrypoint given a user Docker image. To achieve this, we define multiple init containers so that we can run docker inspect during runtime.
Init Containers
Init containers in Kubernetes run before the main container (user-defined app container that executes in the step of a workflow) and they always run in order and run to completion. We need to know the real entrypoint of the user container image to compose the execution script. Essentially we need to run docker inspect at some point. To do this, we define three init containers in Argo, axsetup, axpull and axinit.
axsetup: prepare a static binary (exit 0) and place it in a shared volume with axpullaxpull: pulling the main container image run the static binaryaxinit: rundocker inspectto compose the execution script. Also download the required artifacts from S3 before main container starts
So, why did we choose to use a static binary in the axpull init container? In order to do docker inspect, we need to have the image on the same host as the pod. However, Kubernetes does not support image pulling without a corresponding action. Thus, axpull will pull the image and run nothing but exit 0. The exit 0 executable is from the volume prepared by axsetup.
At this point, once we finish the init stage with the three init containers we will have the execution script ready.
Main Containers
After the init stage, the execution comes to the main containers. There will be two containers running in parallel: the main (user-specified) container and a sidecar container.
- main container: This is the core logic of the step in the workflow. It will run the execution script prepared by the init containers instead of the original entrypoint in the container image.
- sidecar: sidecar container’s job is to record the log from the main container. Also once main container is finished, sidecar container will upload the newly generated artifacts from main container to S3.

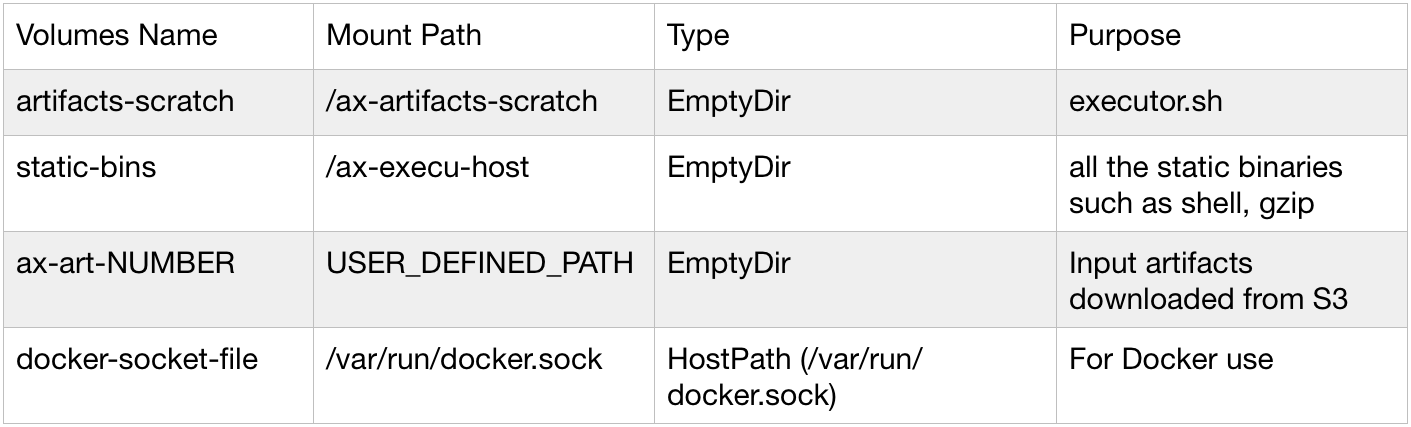
To be able to support running executor.sh for all containers, Argo packages certain binaries such as sh and gzip and injects them into the main container by using volume mounting. Here are volumes Argo mounts to run the main container:
Pros and cons of Argo’s approach
Argo is able to provide seamless artifact management without burdening the user of knowing the container and Kubernetes internals using object storage (for example, AWS S3), Kubernetes volumes and constructs such as init and sidecar containers, and a customized execution script mechanism described above. Here is a high-level list of the pros and cons of the approach we’ve chosen:
Pros:
- Plug and play: users do not need to make any changes to their existing Docker images. This is a major design goal as we wanted to allow users to use any arbitrary containers in a workflow.
- Support for parallel container steps. As discussed in part 1, without shared storage, all the parallel steps in a workflow would need to be scheduled on a single node and that would not be scalable. With this approach, the number of parallel steps in a workflow is only limited by resources of the cluster.
- Persist artifacts in AWS S3 or any S3 compliant object storage. The ubiquitous nature of S3 compliant storage makes the solution portable across clouds.
Cons:
- Unavoidable complexity with the execution script. For certain scenarios, the approach will not work if the entrypoint is expected to run as pid 1.
- Dependency on object storage. Public clouds natively provide object storage, but users may need to be manage one for on-prem installs.
Summary
Argo is a container-native workflow engine built for Kubernetes. One of the primary goals of Argo is to allow users to seamlessly use artifacts generated during the execution of a workflow without the user necessarily modifying their existing container images. In the previous blog post, I covered the various storage options we evaluated for facilitating such artifact management in Argo. In this post, we looked at the implementation details of the artifact management in Argo. We hope that you now understand the innards of Argo’s artifact management.
Please install Argo and give it a whirl and be sure to send your feedback and suggestions for enhancements.
Tianhe Zhang is a member of the technical staff at Applatix, a startup committed to helping users realize the value of containers and Kubernetes in their day-to-day work.

